
Boilerplate to set up your own LLM infrastructure
Keep data on your servers without missing a GPT-like AI power.



Our boilerplate is the framework for your LLM automation
Local translation API endpoint comes with the boilerplate

Content plan generation comes with the boilerplate
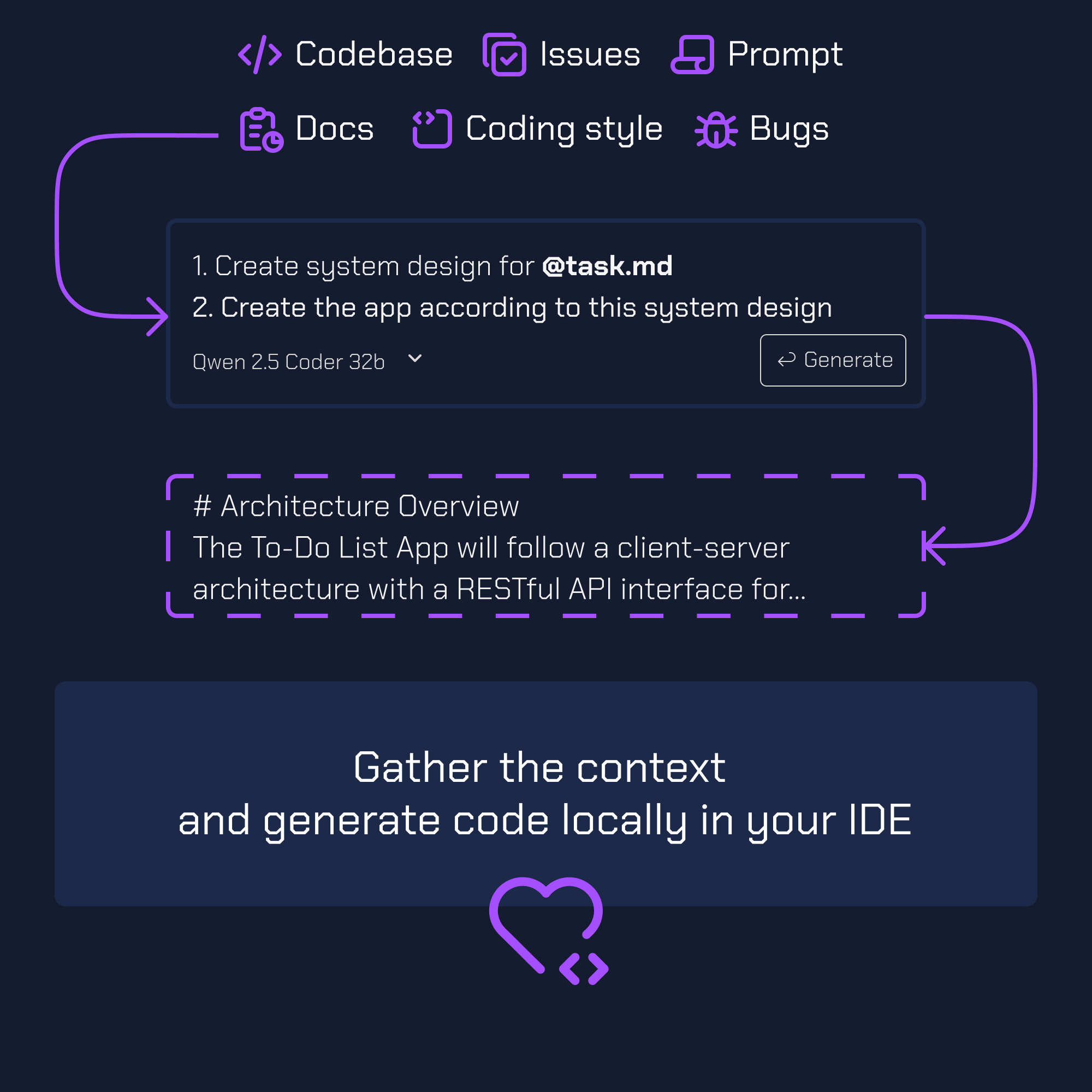
Go from 0 to 1 to N
Seamless LLM production for every use case — business, development, or passion projects.
What's included
Any LLM you want
All opensource models from 🤗 HF are supported. Quantized or not. With reasoning or without.
Task-specific models
We suggest models for every use case (e.g. Qwen2.5-7B-Instruct for following instructions).
Extended context
Use RAGs for both more relevant and extended context via Qdrant engine.
Prompt engineering
Write your own templates and prompts via a templating engine. Keep the logic inside the prompt.
Templates
15 handpicked templates right out of the box. Not hundreds - only the ones you will actually use.
Experimentation
Change your prompts and templates until you get the best solution on your data. Track it in Evidently.
Privacy
Your data and data of your users is secure. Our boilerplate allows LLM to work on your servers only.
Backend
With our boilerplate you can use vLLM, Ollama, Llama.cpp or other backends for your inference.
Metrics
Collect telemetry, visualize it on charts or export reports to see how LLMs impact your business.
Success stories
Our knowledge comes from previously completed projects.
This is the foundation of our boilerplate.

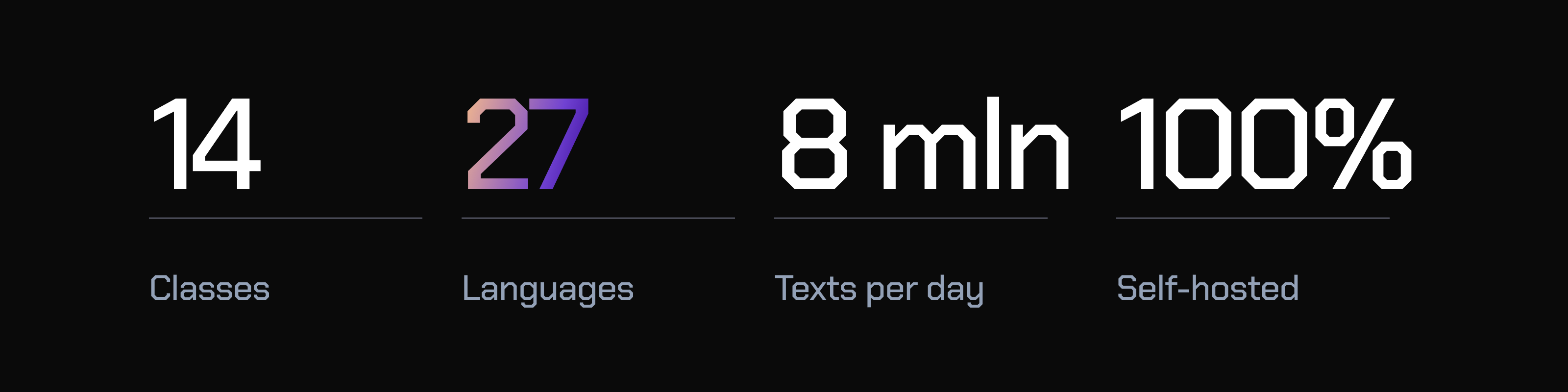
Save weeks on
research and coding
From side-projects to organizations without LLM engineers - we've got you covered.
Frequently Asked Questions
It is an organized collection of prompts with connected RAG and a vector database, an experimentation platform to evaluate models and prompts, and a code to help you easily not only ship your LLM service in production, but also evaluate and improve it.
Yes. The boilerplate in itself doesn't send your data anywhere. It can be stored privately on your machine or servers. You can also process the data on your servers if you choose open-source LLMs. But if you choose to use OpenAI, Anthropic, or other proprietary API, then your data will be processed by them, at a cost of privacy.
It's not a prerequisite because you can always use Continue.dev + Ollama to code in Python with the use of prompts in English. But it sure helps knowing Python basics.
Yes. You can create multi-step workflows with this boilerplate.
You can use OpenAI or Anthropic APIs with this boilerplate but at the cost of privacy.
This boilerplate helps you to launch LLMs but doesn't provide the computational power to run them. There are several ways to get that compute:
- 1. You can use OpenAI / Anthropic APIs so that they can process the LLM request on their side.
- 2. You can rent a GPU server on AWS, Google Cloud, vast.ai, Hetzner, etc.
- 3. You can buy and host your own GPU server.
- 4. You can run it on your device locally for research purposes (a Mac with Apple Silicon will be enough to run a few great models).
Inside the boilerplate we provide models for all budgets.
We use it in the LLM agency to ship models faster, so we update it regularly. Not to mention how fast the industry is going.
After you've got access to the boilerplate, it is yours forever, so it can't be refunded.
Set up your own LLM
Don't waste time on choosing the right stack or ideating on how to evaluate prompts and models.